

How Long Will Testing Take?
A question that deserves a better answer

How Long Will Testing Take?
A question that deserves a better answer
When someone asks, “How long will testing take?” they are often asking the wrong question.
What they usually want to know is:
“How much risk are we willing to accept before we release?”
Testing estimates do not exist to protect a schedule.
They exist to support release decisions under uncertainty.
If you are a practicing tester, you already know the uncomfortable truth:
you cannot predict exactly how long testing will take, because testing is learning, and learning is inherently uncertain.
Your job is not to eliminate uncertainty.
Your job is to make it visible, discussable, and useful.
Why “How long?” is a flawed question
“How long will testing take?” collapses many different activities into a single number:
Learning how the change really works
Investigating side effects and interactions
Retesting after fixes
Exploring what no one thought to specify
Regressing areas that might break, not just those that changed
It also ignores context:
Who is doing the testing?
How well do they know the system?
How risky is failure in this area?
How much risk is the business consciously accepting?
A single date hides these realities.
A credible estimate exposes them.
What skilled testers estimate instead of time
Experienced testers do not start with calendars.
They start with change, risk, and uncertainty.
Time is an output, not an input.
Step 1: Understand what actually changed (not what it’s called)
Before estimating anything, challenge the story you have been given.
Ask:
What changed exactly?
Is this UI-only, or shared logic?
What depends on this code, data, or behavior?
Which assumptions does this change invalidate?
“Small change” is one of the most dangerous phrases in software.
A common failure pattern
A “minor” validation update once broke user creation across multiple workflows because the logic was shared.
The bug escaped because the change was treated as isolated.
Nothing about the change looked risky until users could not sign up.
How to surface hidden impact
Ask developers what files, services, and APIs were touched
Trace workflows that depend on that logic
Review historical defects in the same area
This is informal impact analysis:
change → usage → risk
Step 2: Translate change into risk and complexity
Estimation is not math.
It is professional judgment.
Two lenses matter most.
Complexity: how hard is this to understand and test?
Low: isolated UI or copy changes
Medium: business rules, conditional logic
High: shared components, integrations, data models
Risk: what happens if this breaks?
Low: rare usage, minimal impact
Medium: common paths, workarounds exist
High: core flows, revenue, data integrity, compliance
If you do not trust tester judgment here, no estimation technique will save you.
Concrete examples
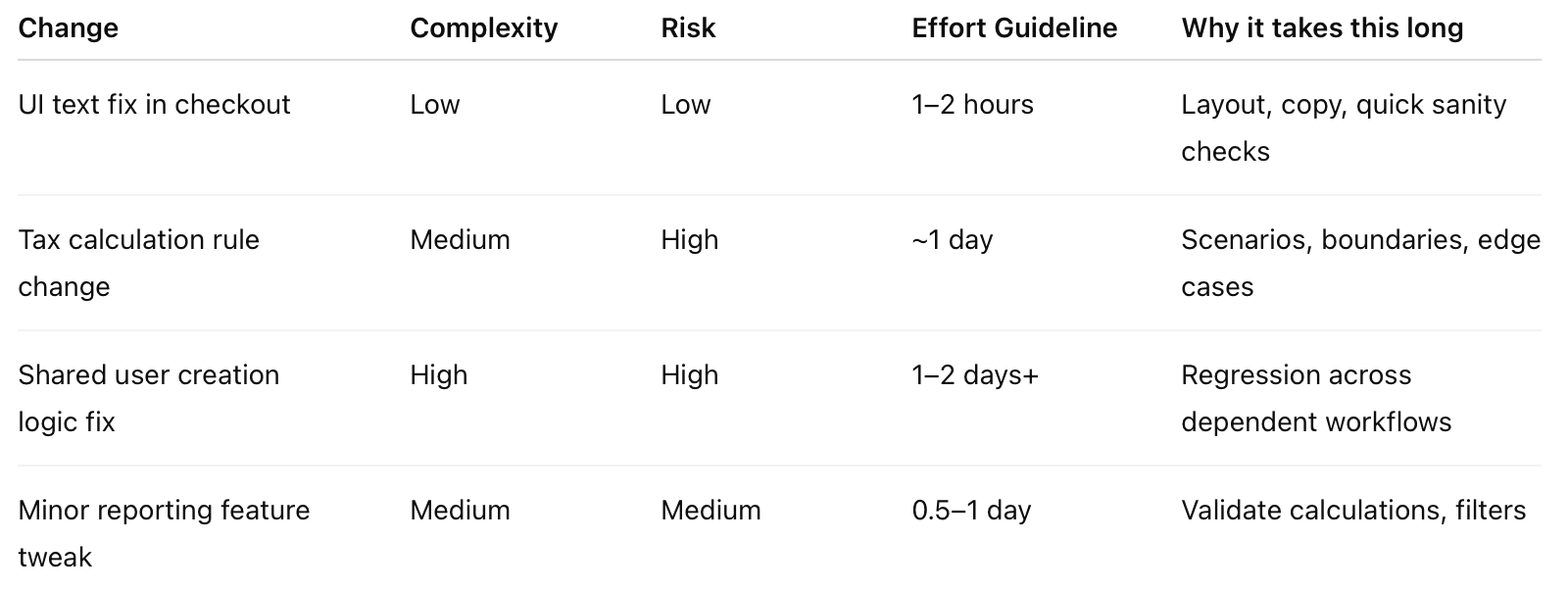
Numbers alone are meaningless.
Reasoning is what decision-makers need.
A useful heuristic (and its limits)
Risk × Complexity → Effort (heuristic)

This is not a formula.
It is a conversation starter.
Always state assumptions:
Stable environment
No upstream refactoring
Existing automation is relevant and reliable
When this heuristic breaks
Unknown architecture
Poor observability or logging
Flaky environments
Last-minute scope changes
Pressure to “just sign off”
If those are present, your estimate must change or your credibility will.
Step 3: Plan regression and exploration deliberately
Regression protects what matters most.
Exploration reveals what no one anticipated.
Both are required.
Regression prioritization heuristics
Frequency of use
Business and data impact
History of failure
Proximity to the change
Regression should be intentional, not exhaustive.
Time-boxed exploratory testing

Exploration without time boxes turns into infinite work and broken estimates.
Treat exploration like an experiment: explore, learn, record, stop.
Step 4: Be honest about people and tools
Time is often driven more by who is testing than what is tested.
Account for:
Domain and system knowledge
Ability to investigate, not just execute scripts
Access to developers for fast feedback
Automation reality check
Does it cover current risks?
Is it stable or noisy?
Does it reduce learning, or create investigation overhead?
Automation can increase confidence.
It can also slow you down. Say which one applies.
Step 5: Give ranges that enable decisions
Avoid fixed dates.
Also avoid meaningless ranges like “1–10 days.”
A good range reflects uncertainty and supports planning.
Example:
“Based on current scope and risk, testing is likely to take 6–8 days.
This includes focused regression and exploratory testing of high-risk areas.
If scope or risk changes, this estimate will change.”
That is not hedging.
That is professional clarity.
Estimation without reporting is theater
An estimate only matters if people understand what it buys them.
Report testing in terms of coverage and risk.
Tested
High-risk components and critical workflows
Sampled
Medium and low-risk areas near the change
Not tested
Explicitly stated, low-usage unchanged areas
Known risks
Identified gaps or fragile behavior
Unknowns
Areas with potential impact but limited time
Overall confidence
Example: medium–high for core flows based on high-risk coverage
Simple risk tables or heatmaps beat status percentages every time.
Common estimation traps
Treating historical effort as a rule, not a reference
Assuming automation equals speed
Ignoring investigation and rework
Hiding uncertainty to sound confident
Every one of these eventually destroys trust.
Final takeaway
Estimating testing time is not about precision.
It is about credibility.
If you can:
Explain risk clearly
Show what was covered and what was not
Make uncertainty visible in minutes
You have done your job.
Testing does not end.
But good decisions start with honest estimates.
Further Reading
If you found this useful, you might also enjoy these articles:


If you found this helpful, stay connected with Life of QA for more real-world testing experiences, tips, and lessons from the journey!